 Happy Little Monoliths is out.
Happy Little Monoliths is out.JSON Schema is nowadays ubiquitous in JavaScript. It's probably the one thing you have heard about I'll mention in this post. It's used by the OpenAPI specification and also Fastify validation via ajv, by default. There are many libraries that make TypeScript integration easy. It gets the job done.
Thing is, I've always found it too be a little too big for most use cases — it goes well beyond what data types and enums to expect, making it possible to combine and define schema rules conditionally. It has substantial validation vocabulary. It can define the specific length of strings and arrays, the number of properties in an object, the type of additional properties, and so much more.
JSON Schema is extremely powerful — but not without its issues.
Specifications matter. When Tim Bray, the author of the XML (W3C) and JSON (IETF) specifications, first expressed his unhappiness with JSON Schema, I didn't give it much thought, because JSON Schema wasn't part of my daily development workflow yet. But his criticism gives some perspective, and correlates with my feeling that it's trying to do much. It has even decided to move away from the IETF standardization process, stating the vision of a stable yet continuously evolving spec doesn't fit well with the IETF process.
ajv's documentation states that "some parts of specification are difficult to implement, creating the risk of implementation divergence" and that it's "complex and error prone for the new users". I can't help but think this is a symptom of avoiding the rigidity of the IETF standardization process.
⁂
Enter JSON Type Definition (JTD), or, RFC 8927, a new standard for defining JSON schemas that has been cooking up since August 2019 and became an experimental RFC in November 2020. Its abstract states:
"Its main goals are to enable code generation from schemas as well as portable validation with standardized error indicators. To this end, JTD is intentionally limited to be no more expressive than the type systems of mainstream programming languages. This intentional limitation, as well as the decision to make JTD schemas be JSON documents, makes tooling atop of JTD easier to build. This document does not have IETF consensus and is presented here to facilitate experimentation with the concept of JTD."
That is to say, the current version of the specification is provided as a means to gain knowledge through experimentation, to see how well it performs fulfilling its purpose, leaving open the possibility of a newer and revised version in the future.
Nevertheless, ajv first introduced support for it in early 2021. Quoting ajv's page on choosing a schema language again, on JTD's benefits:
- Aligned with type systems of many languages — can be used to generate type definitions and efficient parsers and serializers to/from these types.
- Simple to implement, ensuring consistency across implementations.
- Designed to protect against user mistakes.
- Supports compilation of schemas to efficient serializers and parsers (no need to validate as a separate step).
Note how they mention efficient parsers and serializers twice in the same list — that's because ajv can indeed create efficient parsers and serializers from JTD:
- Parsers compiled from JTD schemas [...] can be many times faster in case the string is invalid — for example, if schema expects an object, and JSON string is array the parser would fail on the first character.
- Serializers compiled from JTD schemas can be more than 10 times faster than using
JSON.stringify, because they do not traverse all the data, only the properties that are defined in the schema.
Here's an example of a serializer leveraging the JTDSchemaType helper:
import Ajv, { JTDSchemaType } from "ajv/dist/jtd"
const ajv = new Ajv()
interface Schema {
foo: number
bar?: string
}
const schema: JTDSchemaType<Schema> = {
properties: {
foo: { type: "float64" }
},
optionalProperties: {
bar: { type: "string" }
}
}
const typedJSONstringify = ajv.compileSerializer(schema)
Granted, Fastify accomplishes the same with fast-json-stringify, which uses JSON Schema as input, but ajv's JTD-based serializers have comparable performance.
There's also Typia, which appears to be over two times faster than fast-json-stringify in some cases. I haven't personally tried it yet, but it would play nice with JTD schemas because it focuses on pure JavaScript structures (via TypeScript interfaces), leaving value validation to comment tags.
Trivia: RFC 8927's author, Ulysse Carion, has a blog, though it hasn't seen new entries in over two years. His piece on implementing RFC 3339 caught my attention — it shows the level of attention and dedication in enhancing programming language support for JTD's timestamp type.
JTD Syntax
I'm not going to cover the entirety of JTD here — head over to Learn JTD in 5 Minutes for that — but rather focus on a few things I really like.
There's no need to set type to object when defining objects, instead you simply set properties, optionalProperties and additionalProperties (a boolean, like in JSON Schema). For defining arrays, you set an elements property.
Also, every rule can have a nullable property and a metadata property, which can take custom properties. Below is a minimal JTD example featuring required and optional properties, strings, numbers, booleans and arrays:
{
"properties": {
"firstName": {
"type": "string"
},
"lastName": {
"type": "string"
}
},
"optionalProperties": {
"phones": {
"elements": {
"type": "string"
}
},
"age": {
"type": "float64",
"nullable": true
}
},
"additionalProperties": true
}
Note the use of float64 to represent a JavaScript number in its full capacity. There are several number types supported by JTD, since its designed to allow code generation in multiple languages.
JTD supports tagged unions by allowing you to set a discriminator — the key that will be used to differentiate how objects are validated, and a mapping with each possible schema. In the schema below, the object can be validated against all nested objects defined under mapping, depending on the value of the eventType key, which can be either USER_CREATED, USER_PAYMENT_PLAN_CHANGED or USER_DELETED:
{
"discriminator": "eventType",
"mapping": {
"USER_CREATED": {
"properties": {
"id": { "type": "string" }
}
},
"USER_PAYMENT_PLAN_CHANGED": {
"properties": {
"id": { "type": "string" },
"plan": { "enum": ["FREE", "PAID"] }
}
},
"USER_DELETED": {
"properties": {
"id": { "type": "string" },
"softDelete": { "type": "boolean" }
}
}
}
}
In JTD, you'll miss the ability to set the constraints on values that are available in JSON Schema, because JTD focuses on data types, with enum being the only exception that allows you to say a property should have one or more specific values. Any other kind of value validation, you'll need to do on your own.
The lack of granular data validation in JTD definitely doesn't make abandoning JSON Schema easy if you rely heavily on that — and one might say in 99% of the use cases, JSON Schema is just about good enough. The choise of using JTD is more of a philosophical and architectural nature, and a deliberate preference for simplicity. And perhaps, IETF-backed specifications.
Just for fun, here's how you can leverage the metadata property in JTD to add arbitrary validation rules in pure JavaScript, through pre-compiled Function instances. Consider the following schema:
{
"properties": {
"person": {
"properties": {
"age": {
"type": "float64",
"nullable": true
}
},
"additionalProperties": true,
},
},
"metadata": {
"rules": [
"person.age > 0"
]
}
}
We could write a function that first parses a JSON string validating it against the limited-scope JTD schema, and then subsequently applies pre-compiled functions based on each rule defined under metadata.rules. We need to capture all top-level property key in the schema, so they can be destructured and referenced directly in each rule, and then just execute them one by one:
import Ajv from 'ajv/dist/jtd.js'
import uri from 'fast-uri'
// Same options used by Fastify
const ajv = new Ajv({
coerceTypes: 'array',
removeAdditional: true,
uriResolver: uri,
addUsedSchema: false,
allErrors: false,
})
class RuleNotSatisfiedError extends Error {
}
function makeParserWithAdditionalRules (schema) {
const parse = ajv.compileParser(schema)
const rules = []
const allProperties = [...new Set([
...Object.keys(schema.properties ?? {}),
...Object.keys(schema.optionalProperties ?? {})
])]
for (const rule of schema.metadata?.rules ?? []) {
rules.push({
source: rule,
exec: new Function(`{ ${allProperties.join(', ')} }`, rule),
})
}
return function (json) {
const result = parse(json)
for (const rule of rules) {
if (!rule.exec(result)) {
throw new RuleNotSatisfiedError(rule.source)
}
}
return result
}
}
const parse = makeParserWithAdditionalRules(schema)
console.log(
parse(
JSON.stringify({
person: {
firstName: 'Joe',
lastName: 'Pesci',
age: -1
},
})
)
)
RuleNotSatisfiedError: person.age > 0
at file:///Users/jonas/Play/parse.js:63:15
at file:///Users/jonas/Play/parse.js:34:3
at ModuleJob.run (node:internal/modules/esm/module_job:193:25)
at async Promise.all (index 0)
at async ESMLoader.import (node:internal/modules/esm/loader:526:24)
at async loadESM (node:internal/process/esm_loader:91:5)
at async handleMainPromise (node:internal/modules/run_main:65:12)
Also strongly recommend checking out better-ajv-errors.
As long as there's no chance of your JTD schemas ever being tampered with by malicious parties, it's perfectly fine to use this — note that both fast-json-stringify and ajv use new Function. What would really be nice is having something like Anton Medvedev's expr in JavaScript — we're really missing something like that!
JTD Syntactic Sugar
I've just released v1.0.0 of jsontypedef, a syntactic sugar library I wrote for JTD. Yes, I shamelessly grabbed jsontypedef from npm while it was still available. I think I'm honoring it well though, now that it includes 43 tests:
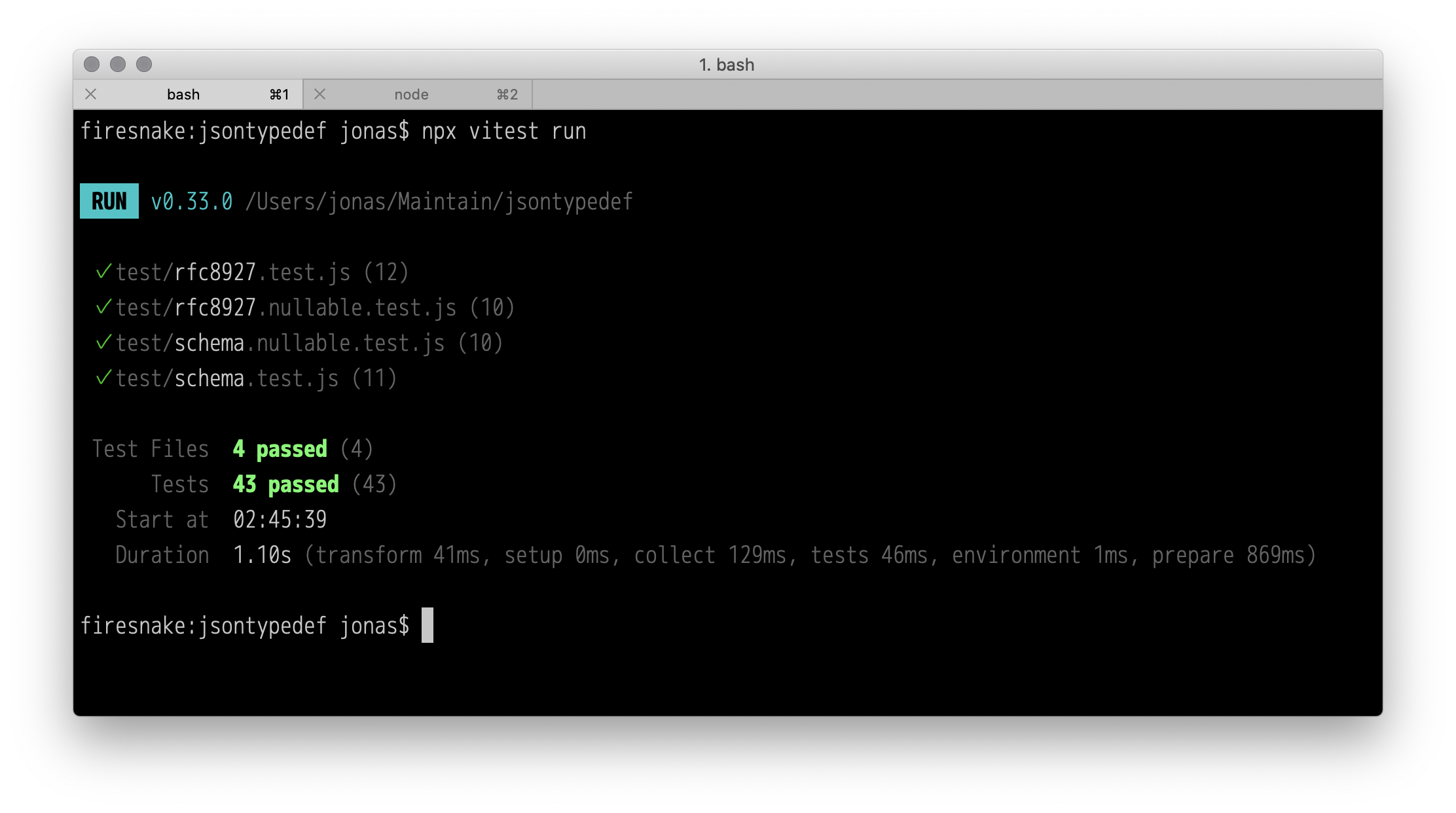
With it, you could have written the previous JTD schema where I played with picking up custom rules from the metadata property as follows:
import jsontypedef from 'jsontypedef'
const { sealed, object, nullable } = jsontypedef
const schema = sealed({
person: object({
age: nullable.number()
}
}, null, {
rules: [
'person.age > 0'
]
})
Note that the second parameter for sealed() is null, because there are no optional properties, the signature is (props, optionalProps, metadata). For convenience, the library differentiates objects with and without additional properties as object() and sealed(), respectively — both with the same signature. There's a JSON Schema compatibility helper that lets you define schemas with the same API but get JSON Schema instead — useful for Fastify:
import Fastify from 'fastify'
import jsontypedef from 'jsontypedef'
const { object, string } = jsontypedef.schema
fastify.post('/the/url', {
schema: {
headers: object({
'x-foo': string()
}),
},
handler (req, reply) {
reply.send('ok')
}
})
Fastify of course recommends fluent-json-schema for the same purpose, but I've found my JTD version to be a little less verbose.
Here's an example using fluent-json-schema:
const schema = S.object()
.title('My First Fluent JSON Schema')
.description('A simple user')
.prop('email', S.string().format(S.FORMATS.EMAIL).required())
.prop('password', S.string().minLength(8).required())
.prop('role', S.string().enum(Object.values(ROLES)).default(ROLES.USER))
And with jsontypedef:
const schema = object({
email: string(),
password: string(),
role: values(Object.values(ROLES)),
}, null, {
title: 'My First Fluent JSON Schema',
description: 'A simple user',
})
Note that the second parameter of jsontypedef.object() is reserved for optional properties, and in this case there are none. A lot of the reduced verbosity has to do of course with the fact JTD doesn't include the granular data validation rules from JSON Schema, but if you're not using them, it's worth the noise reduction!
⁂
Before wrapping up, here's another bit of trivia: perhaps not really trivia, but I'm guessing you never heard of RFC 8610, or, Concise Data Definition Language (CDDL). It's used in RFC 8927 to describe JTD itself:
properties = (with-properties // with-optional-properties)
with-properties = (
properties: { * tstr => { schema }},
? optionalProperties: { * tstr => { schema }},
? additionalProperties: bool,
shared,
)
with-optional-properties = (
? properties: { * tstr => { schema }},
optionalProperties: { * tstr => { schema }},
? additionalProperties: bool,
shared,
)
That's when I learned about Carsten Bormann, the author of CDDL, CBOR and many other RFCs. cbor-node has over 250k weekly downloads on npm. I had never heard of it before, but it must be pretty useful. Carsten has been authoring RFCs since 1998 and recorded a nice little video explaining CDDL and its history. CDDL actually looks great and seems to enable a lot of the same features of JSON Schema. Unfortunately the JavaScript tooling doesn't seem to be mature enough yet, if only ajv would support it!